It's ironic. Accelerators exist to help founders run and optimise their businesses, but the accelerator operations themselves are full of similar inefficiencies they'd flag in a portfolio company. I've been looking at information flows inside accelerator programs recently, and the problems aren't obscure. They're hiding in plain sight.
The Knowledge That Disappears
Accelerators run on three things: partner expertise, networks, and institutional pattern recognition. The problem is that all three are ephemeral from a systems perspective.
A partner sits with a founder for an hour. They share hard-won insight about GTM, hiring, fundraising, product. The founder takes notes. The partner moves on to the next meeting. That conversation is effectively gone. The next founder with the same question starts from zero, and the partner repeats themselves for the hundredth time.
Partners know this. Some are building their own personal workflows to scale their efforts. But the real unlock isn't just compounding one partner's knowledge. It's combining it with that of their peers.
This isn't a people problem. It's a systems problem. And it compounds negatively across cohorts in a way that quietly costs accelerators enormous leverage.
Why This Is Harder Than It Sounds
There are plenty of tools that help organisations parse and query knowledge bases. Build a RAG pipeline, embed your documents, let people ask questions. Solved.
Except it isn't. Not for accelerators.
The challenge: the same question means something completely different depending on who's asking it.
"How do we convert free users to paid?" from a first-time solo founder, pre-revenue, building in a regulated vertical with four months of runway is a fundamentally different question than the same words from a second-time founder at seed stage with an enterprise pipeline.
Generic knowledge bases don't know the difference. They return the same answer to both. One founder acts on advice that was never meant for them, and wonders why it didn't work.
Archetype-Aware Retrieval
What accelerators need isn't a knowledge base. It's a knowledge system that understands who's asking before it answers, and gets smarter with every interaction.
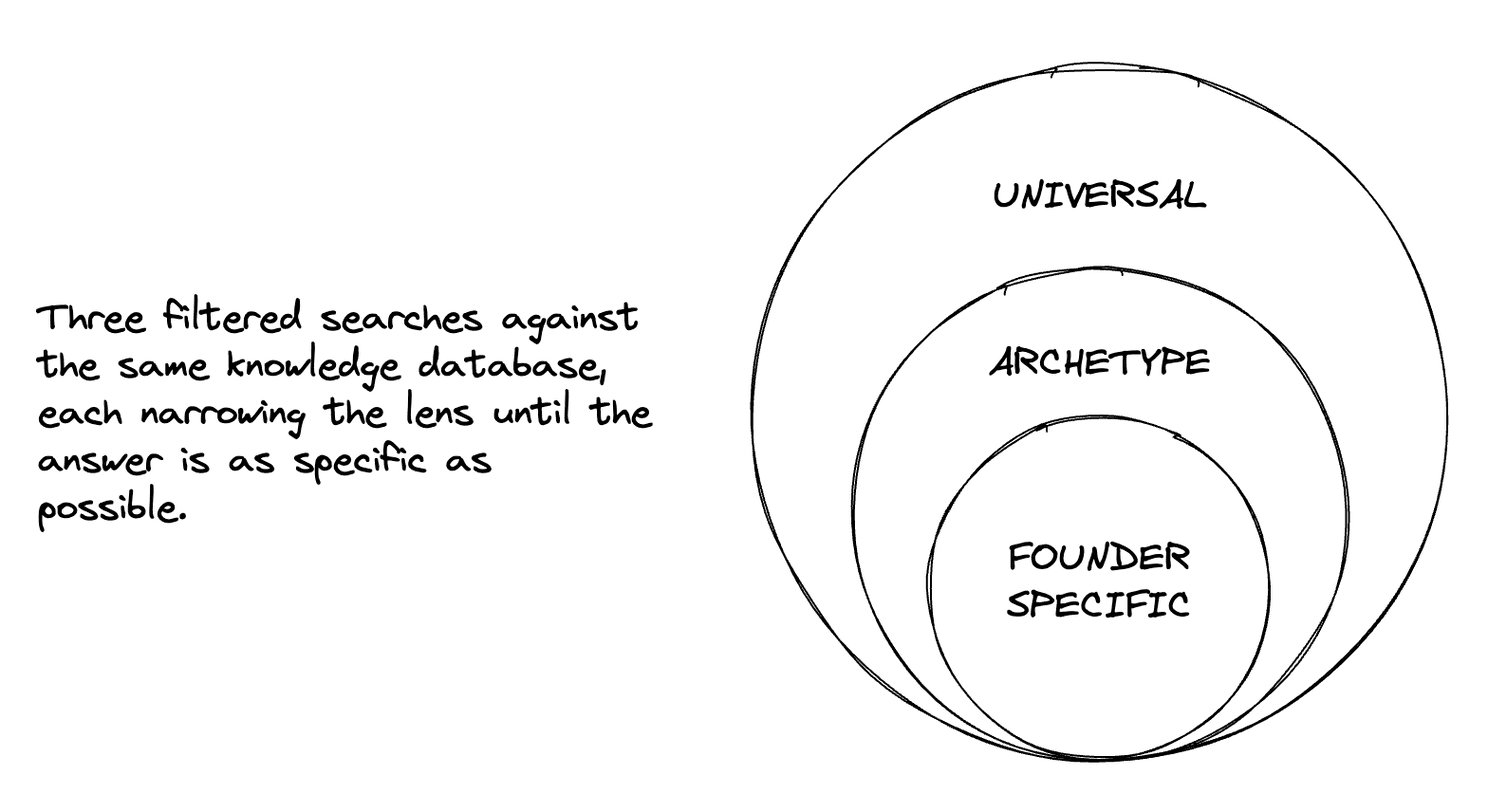
The core idea is what I'm calling archetype-aware retrieval. Every piece of knowledge in the system (partner expertise, founder execution patterns, operator scar tissue, network context) gets tagged not just by topic, but by who it's relevant for. Five dimensions define a startup's constraint profile: category, stage, product maturity, founder experience, and team composition.
When a founder asks a question, the system doesn't just search for relevant content. It filters to their specific profile. A first-time founder building B2B SaaS in alpha gets advice validated for that exact combination of constraints, not generic startup wisdom dressed up as insight.
Implementation: a RAG system with a metadata layer mapping to the archetype dimensions. Three filtered searches run in parallel (universal knowledge, archetype-specific knowledge, company-specific context) and the results are synthesised by an LLM into a single coherent answer. The system prompt ensures the model knows who it's talking to before it generates a word.
The answers get more specific and more useful over time. Not because the model gets smarter, but because the memory does.
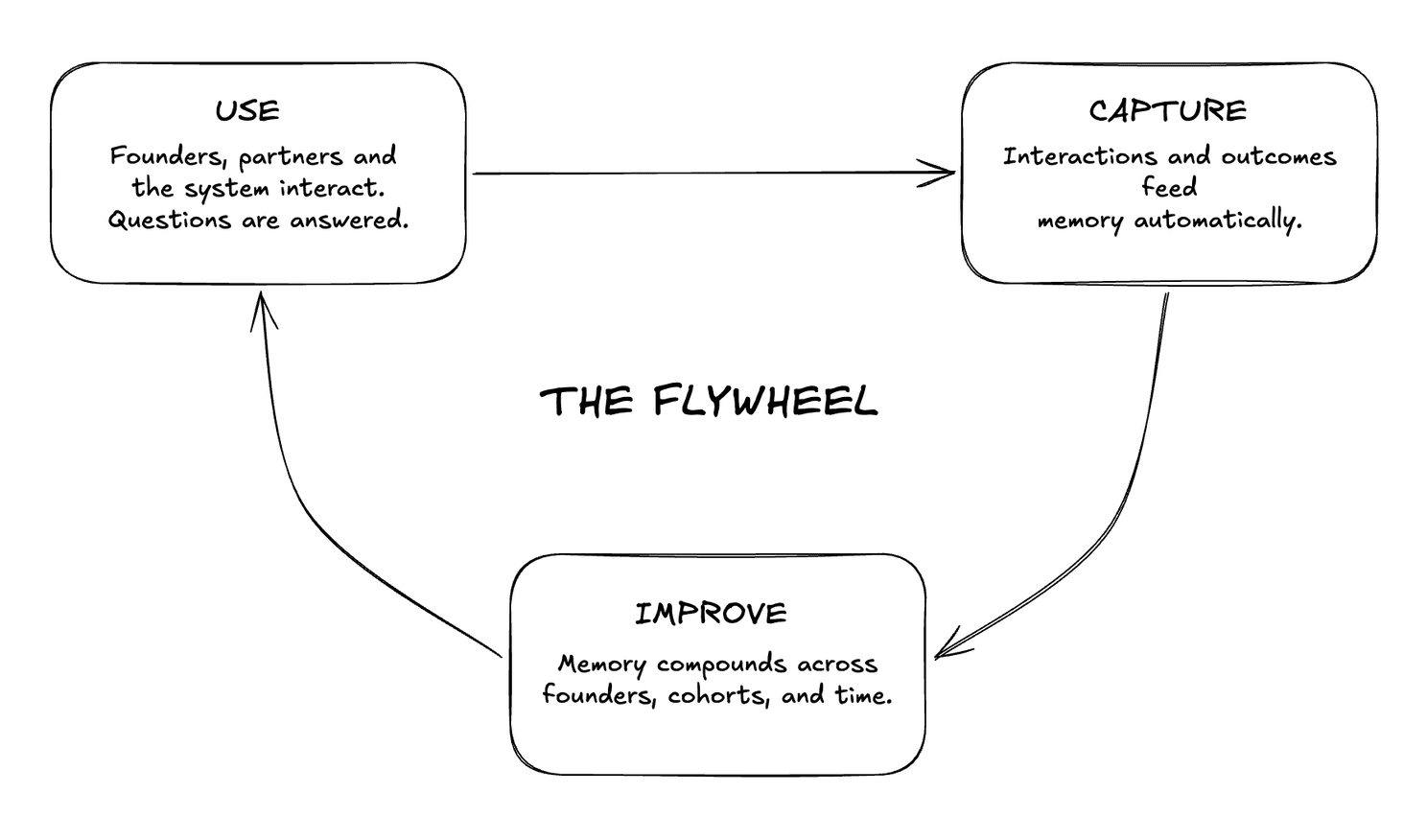
The Compounding Effect
Here's where it gets interesting for accelerators specifically.
Every interaction feeds the system. A partner pushes a 1:1 summary. A founder asks a question in a shared channel and the system answers with archetype context, which naturally filters who responds. Founders and partners who recognise their own constraints engage. Their contributions get embedded. The memory improves.
Each cohort makes the next one smarter. That's not a feature. It's a compounding asset. And in a market where most accelerator programs reset to zero every twelve weeks, compound knowledge is genuine alpha.
How You Know It's Working
Three metrics :
Adoption rate.
Questions asked and answered through the system. If founders trust it, they use it. Usage is the leading indicator that the memory is pulling its weight.
Archetype match rate.
The percentage of answers rated relevant by founders of a specific profile. This is the metric that proves the system is doing something a generic knowledge base can't. If match rates are high for narrow profiles, the constraint tagging is working.
Time-to-useful-answer.
How fast a founder gets to actionable advice compared to the previous cohort's baseline. This captures the compounding effect directly. If cohort N+1 gets better answers faster than cohort N, the system is earning its keep.
The Risks Worth Taking Seriously
No system like this ships without friction. A few honest risks:
Cold start
The memory starts empty. Mitigation is seeding with existing knowledge: partner playbooks, previous cohort notes, curated external frameworks. Day one value comes from surfacing what already exists, not generating what doesn't yet.
Knowledge quality
A confident wrong answer is worse than no answer. Emoji reactions and follow-up threads provide lightweight quality signals. More importantly, the system surfaces relevant 1:1 topics for partners, which creates a passive audit loop. Outcomes get discussed. Memory gets corrected.
Privacy
Founders share sensitive information. The system surfaces patterns, never individuals. "Founders with your profile who tried X saw Y outcome," not "Company Z struggled with this." That principle is non-negotiable and gets enforced at the system prompt level from day one.
Who This Is Really For
It's tempting to frame this as a founder tool. It isn't. It's a partner scaling tool whose output benefits founders.
Partners are the bottleneck. Their time, their memory, their ability to give the right advice to the right founder at the right moment. That's what constrains how much value an accelerator can deliver. This system doesn't replace partner judgment. It compounds it.
For founders, the benefit is real but secondary: faster access to more relevant advice, from a system that already knows their constraints before they have to explain them.
For the accelerator as an institution, the benefit is structural: a knowledge asset that grows with every cohort, doesn't walk out the door when a partner moves on, and makes the program more valuable over time instead of starting from scratch every twelve weeks.


